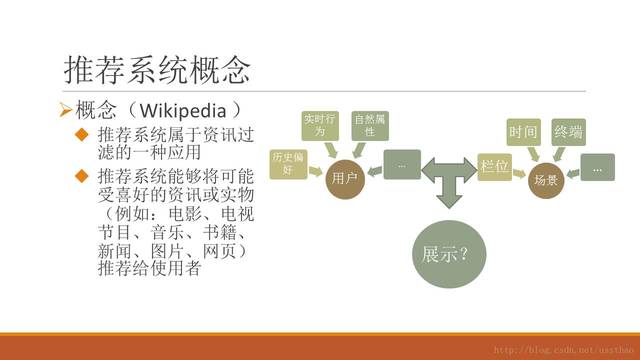
推荐系统实战
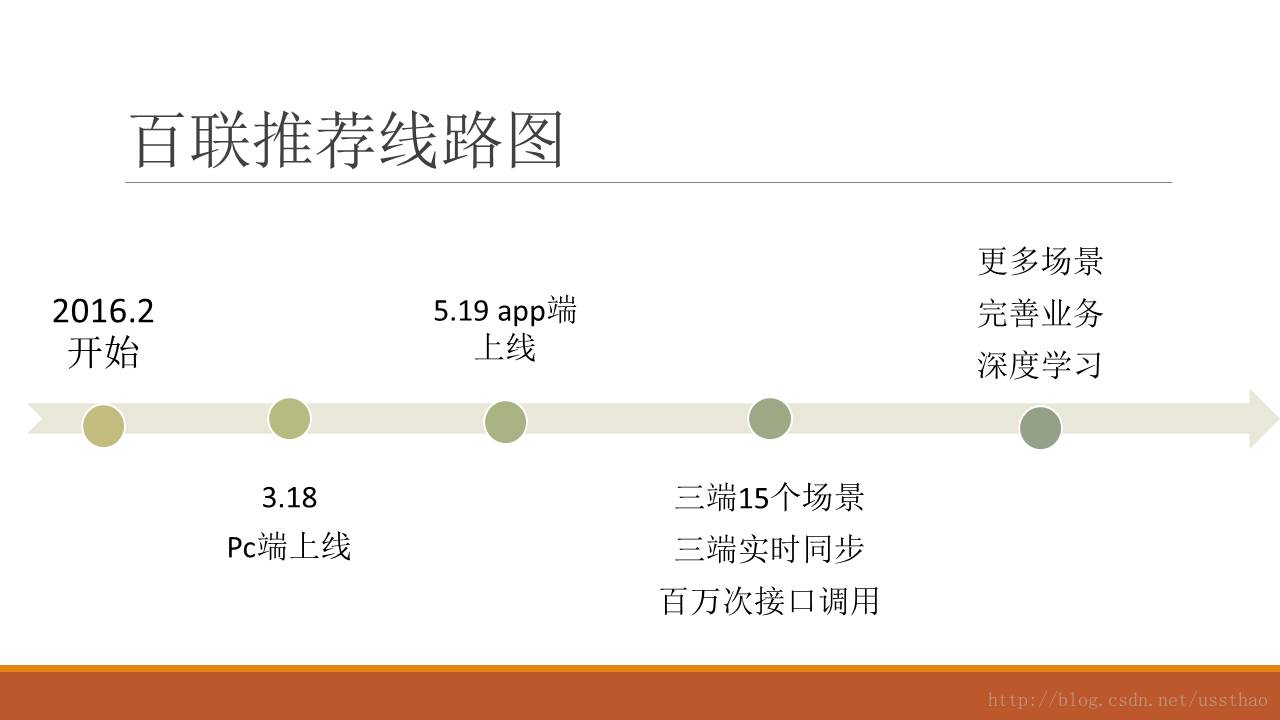
今天在朋友圈看到一篇“一号店从0到1构建推荐系统通用平台”,突然感觉很有感触,上线八年的一号店从0到1构建,那我们这个5.19上线的百联o2o平台,推荐系统说是从-1爬到0.x更确切。很多时候看到都是某大型电商或互联网平台某个系统的架构图,这个架构图都很高大上,似曾相识,展示的都是很美好的一面。很少有人介绍在实现这个系统最初遇到的各种问题,因为电商发展至今,最初的那几个人早已已经成为技术总监或者cto了,都已经功成名就出书立传了。如果感兴趣可以看看专著《大数据架构商业之路:从业务需求到技术方案》豆瓣好评推荐。
虽然之前也曾接触过推荐系统,但也都是其中的某个算法,或者说大一点其中的某个栏位。也看过《推荐系统实践》这样的图书,现在反观一下,感觉这些更像是一本介绍推荐算法的书,而不是能落地的一套系统。在这里就是想记录一下,在百联全渠道(bl.com),和另外一个同事踩坑排雷实现百联推荐系统的一个过程。希望后来者能从中吸取教训。这篇文章没有高深架构图,复杂逻辑图,基本凭记忆,用文字讲述俩人历时4个月构建一个推荐系统雏形的历程。
数据准备阶段
商品数据
首先要了解数据,电商就是贩卖商品的,与商品相关的一些概念包括商品(sku),产品(spu),属性、品类,自营、商城(商家)等,在这个阶段先了解一下商品和产品。借用某东的解答:spu就是一个苹果6s, sku就是银色苹果6s、灰色苹果6s 。这种一个携带基本属性的spu,衍生多个sku的情况在服饰类里最多见,同一款衬衫对应不同颜色、不同尺码。
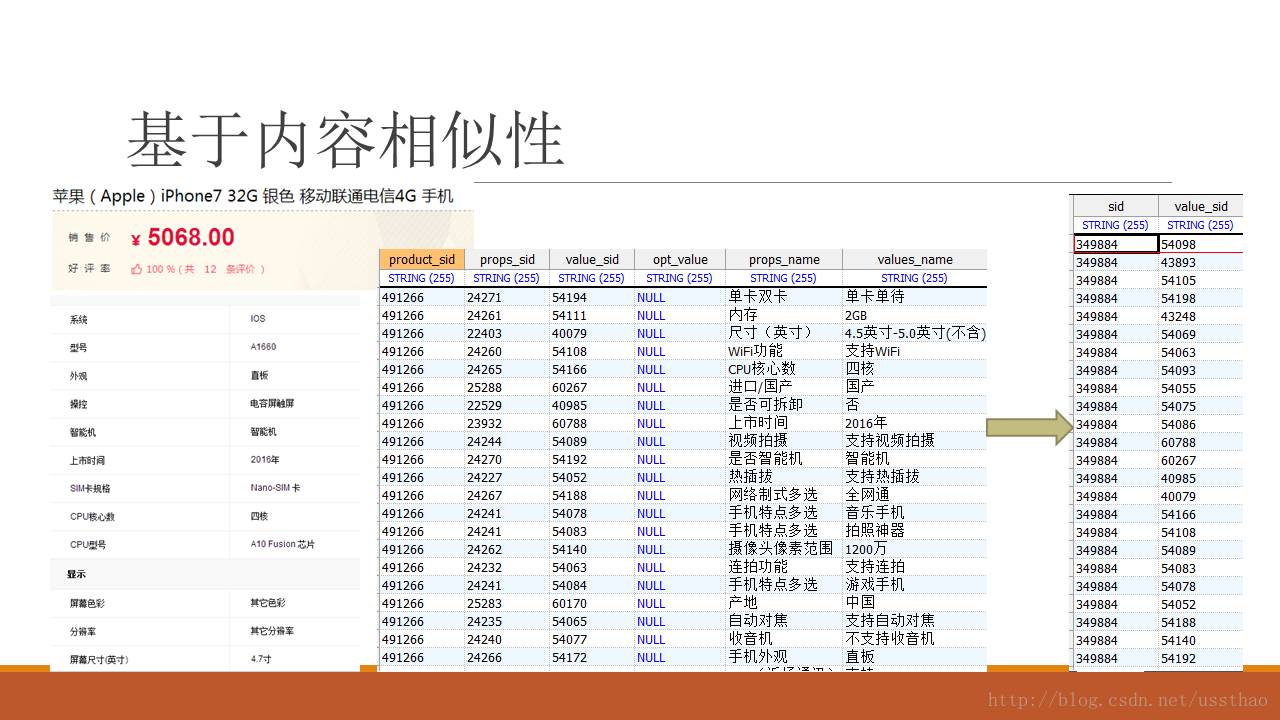
一个spu 有多个属性,不同spu有不同属性,属性又分为属性和属性值。属性和属性值又分别用key,value表示。看个简单例子,手机苹果(Apple)iPhone 6S 64G 玫瑰金色移动联通电信4G手机,在百联商品ID是248397,对应的产品ID是30277,其中部分属性如下表,在数据库里面产品的一条属性,包括(roduct_sid,props_sid,values_sid)三项。这张表的数据在后面做推荐的时候还会用到。可以看到这里面没有价格,价格是和商品绑定的,顺便广告一下,即时价格是5188,和某东某店价格差不多,但保证有货,而且,尤其预约抢购的产品可以来百联(bl.com)看看。

再一个概念就是品类,对于品类不同的平台有不同的划分和叫法,总之有前台类目,后台类目。一个商品依据其功用划分到一个后台类目,后台类目可以映射到多个前台类目。例如手机的类目层级就是这样手机数码/电脑办公>手机通讯>手机。顺便说一下,这个类目导航叫面包屑导航,来自童话故事”汉赛尔和格莱特”,作用是告诉你目前在网站中的位置以及如何返回。
当然情人节来临的时候,网站类目多了个情人节礼物类目,也可以把手机这个类目映射到情人节礼物这个前台类目上。例如在1号店手机这个类目也可以映射到送男士这个类目下,创意礼品、礼品卡>送男士>数码通讯>手机>。至此与商品相关的数据基本够用了。接下来需要了解与用户相关的数据。
行为数据
对于用户产生的数据可以概括为何人(user_id)在何时(time)、何地(gps坐标,ip)对何种商品(item_id)通过何种渠道(channel_id)产生了何种行为(behavior_type ),这样的数据格式和阿里推荐大赛数据格式基本一致。数据来源可以通过埋点和日志收集获得。

这里用到的是用户ID,用户在pc端访问时,通常不会登陆,那么只能取到系统的一个cookie_id,cookie_id和user_id可能出现多对多情况。我们主要通过把cookie_id绑定到紧邻其后第一个登陆的user_id来把cookie_id绑定起来,丰富用户行为。至此,必要的数据已经准备完了,接下来就要实现推荐栏位了。
实现推荐栏位
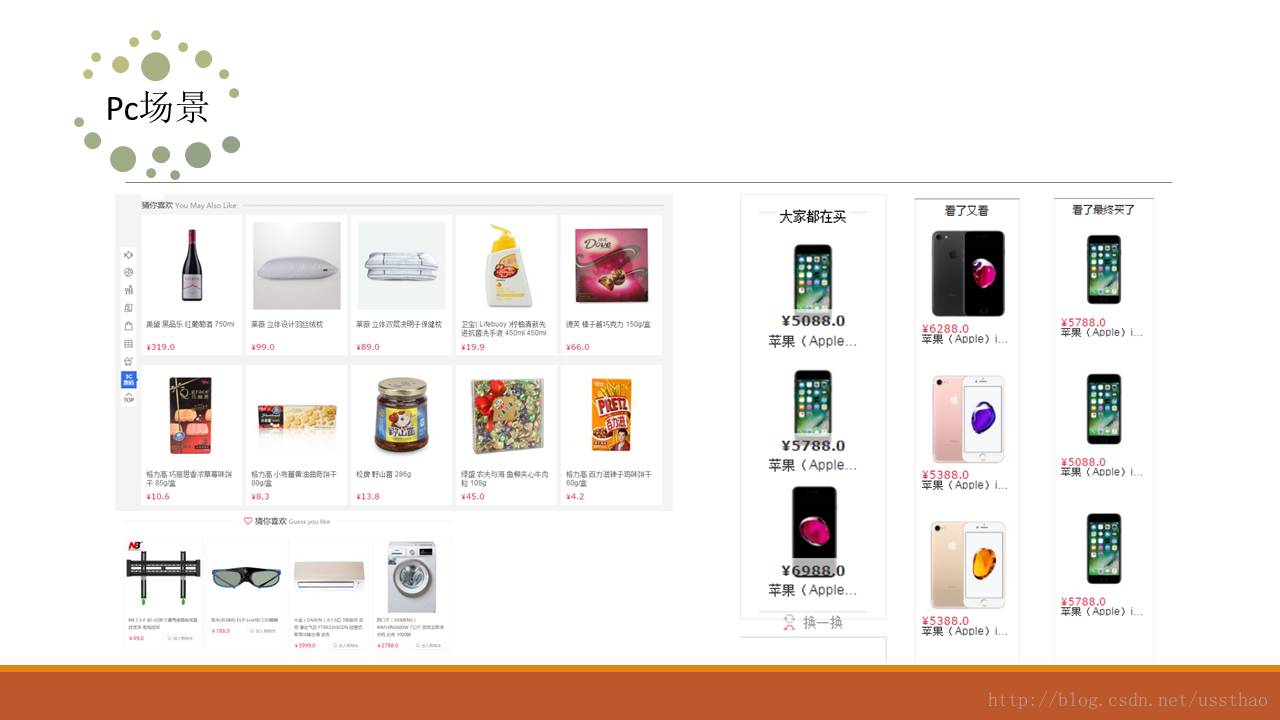
了解完数据结构,组织数据到此已经过了半个月了,要在一个月以内跑通推荐系统流程,就要立刻着手搭框架,上算法编接口了。此时还没产品经理,就按照老套路,先对详情页栏位入手,“看了又看”、“看了最终买”,“买了还买“,有了这三个栏位,推荐系统基本完成大半。既然大数据,那大数据工具一定还是要用一下,spark风头正盛,刚好公司也倡导,就用spark了。幸好在跳槽前学过一周快学scala,那就直接上手吧,看了又看,买了还买之类的简单关联采用简易bayes实现起来都不是问题。于是和另外一个同事,开始编写离线数据处理的部分,处理结果就是对于某个商品,如果是看了又看栏位,该给它推荐哪些商品。很快离线处理部分就结束了。Hive里面的原始数据,经过spark处理,写到了redis,再写个接口,传入一个商品ID,在redis一读取返回几个商品id就结束了。
此时应该过去有一个月了,就剩接口开发了,当时想,这个太简单了,一个栏位给一个接口,一天就搞定了。虽然百联还未正式对外宣布上线(5.19百联全渠道正式加入电商大家庭),但是也是对外访问的接口,健壮性还是需要的,那还是要搭个可靠的架构,部署俩tomcat,前端加个nginx做负载均衡,再申请个二级域名。Redis也配成master_slave模式。后面开发猜你喜欢接口,主从模式的redis遇到很多问题,无奈改用redis集群,由此引起接口整个重构。
架构搞定了,开始写接口,通过接口返回结果发现,返回的商品个数参差不齐,很多商品都无用户行为。只靠离线处理结果,无法满足栏位需求。需要制定每个接口返回商品规则,
以“看了又看”为例,最终一个栏位获得的5个或者的,10个商品,就是按照如下顺序得来,基本上踩一个坑加一项。真是如一位同事讲的“都开始怀疑人生了”,此时之前的一位同事已经离职,又新进一位同事。

这个规则的最低目标是,推荐栏位不能留白,这一条由“热门随机商品”来保证。在满足最低目标的情况下还要最求品质,首当其冲的是用户行为产生的推荐结果,这是大数据落地的表现。对于无用户行为的商品(未必是新品),推荐相似商品。如果是新品,无相似商品的推荐同品类下随机商品。本以为到这里坑踩得差不多了,不成想有的品类下只有一两个商品,没办法用兄弟类目下商品来补。
一个坑补一段代码,一个栏位复制粘贴一下,到此代码已经惨不忍睹,但是还是奔着之前的规划在前进,先可用再追求易用。虽然此时代码已惨不忍睹了,我还跟这位刚来的同事打了一个比喻,我指着窗外的高楼说,你看盖楼的,都是浇筑框架,再装修,怎么不盖一层装修一层。这句话对同事产生了重大影响,虽不能受用一生,估计也要懵一阵。
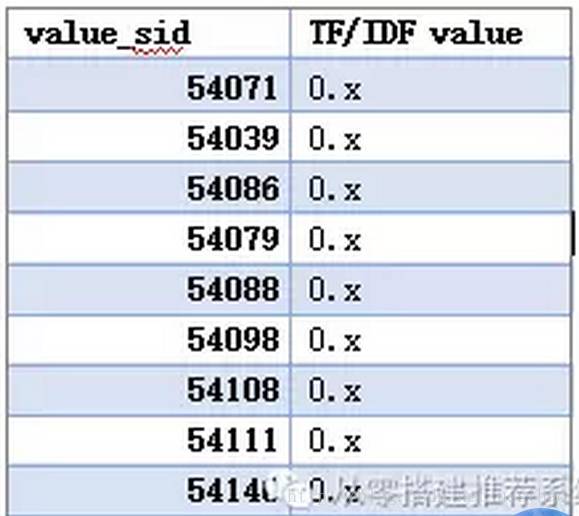
这里再补充几个细节,第一就是相似商品计算,其实就是根据商品本身的属性计算相似商品的相似性。每个属性有个权重,这个权重采用tf/idf,如果拥有某个属性的商品越多,那么该属性,权重越小。每个商品用属性来表示,两两计算余弦距离。如果计算两个文档相似性,估计大家更容易理解。用在两个商品上,估计还需要思维转换一下,文本不都是字词吗,怎么就是54071,54039……。计算的时候商品限定在同一品类下,把value_sid映射到一个向量空间,这个空间的维度是一个常数,也许会设置很大。
推荐接口返回哪些内容哪,一般情况下,都是返回一串商品id,调用方再去查询商品价格、图片,标题、库存。当时也是这么想的,最后只提供推荐商品ID,这样推荐系统风险、责任也小一点。但是必须携带的信息还是要准备的,这个初衷还是想方便自己查看到底推荐出来的是什么东西。还有一个附加信息就是这个商品到底出自哪个“坑”,以“看了又看”为例,每个商品后面都跟着一个商品来源,是来自用户浏览,还是相似商品,或者其它的”坑“。
百联在没有推荐之前,前端都是调用搜索接口,在该类目下随机取几个商品,商品价格、库存一起取来。当时一种方案是推荐出来的商品ID,传给搜索接口,取回实时商品信息。这个方案其实两方都不喜欢,搜索感觉增加负担,增加风险。我们推荐也感觉延迟太大。既然我们必要信息都有,那么就取我们自己的商品信息。为了减少不T+1数据更新带来的不一致,最初想把搜索实时数据接过来,可最终也没成,还打击了离职同事的自尊心。无奈只能增加从百联“中台”数据库更新的频率。每天更新三次,这三次中间出现的不一致就无能无力了。就这样,详情页三个栏位基本上线了。偶尔价格不一致,也没出现大的问题,无非是同spu商品个数过多等小问题。
至此走通了从数据抽取、数据处理、数据存储到接口提供的整个流程,就如标题写的一样,都不算是一个系统。至此大概俩月过去了,接下来就应该实现电商里面推荐重头戏“猜你喜欢”了。
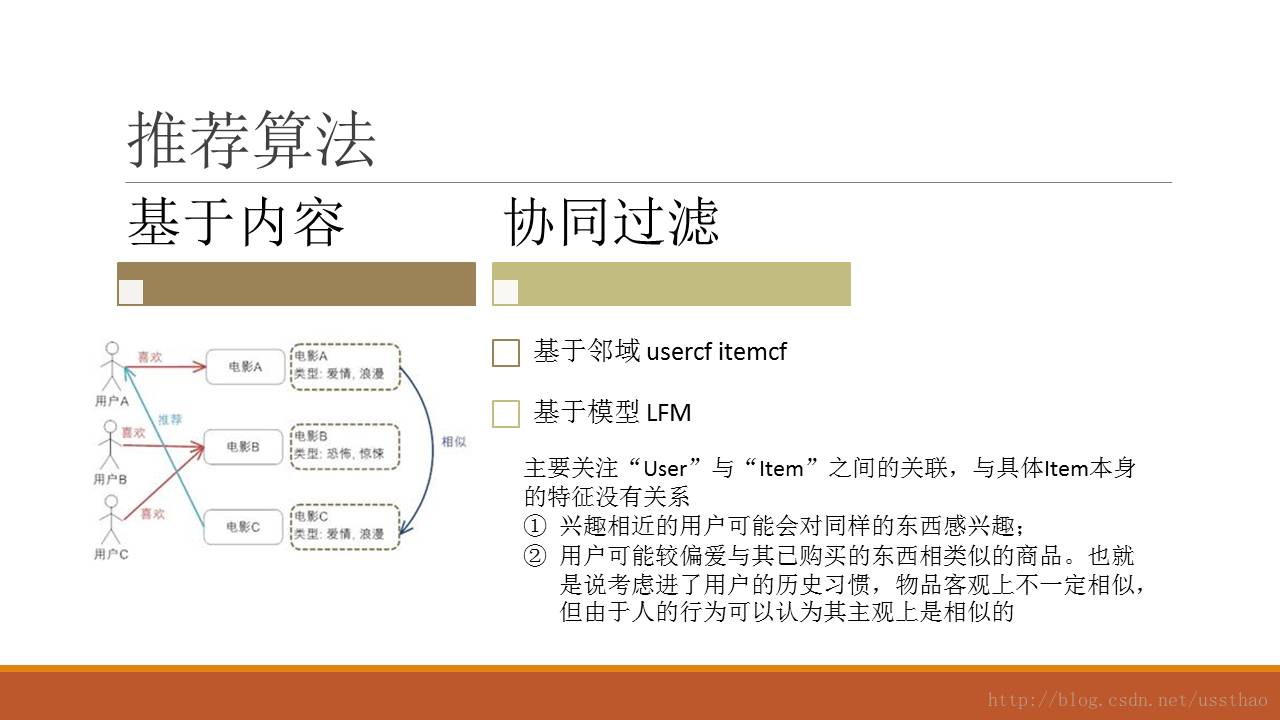
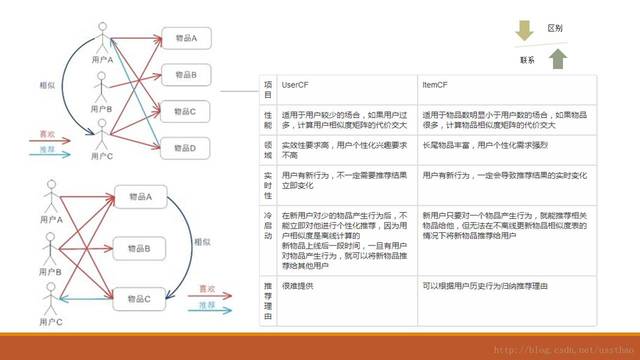
这个栏位算法主流就是基于邻域或者模型的协同过滤算法。算法不是首要考虑的问题,既然平台用到了spark,当然首选就是als。既然算法没问题,重点就是数据了,算法应用案例都是用户评论打分这样的显示反馈。从之前经验知道,很多用户购买不评论,评论的也只为赚积分,有的人文字描述是差评打分是五星。加之系统刚刚上线,用户购买少,购买的商品基本偏向食品、零食之类的商超品类。为了增加推荐新颖性和多样性,先用用户浏览行为做一版,对浏览行为给个权重,随日期衰减和累加。数据套入算法,根据接口要求取打分最高的topn。未登陆或新用户给推荐热门,把一天时间分为早中晚时间段,分别推荐该时间段热门浏览的或者爆款,为了多样化,随机选取。至此好像这个栏位比性情页来的还要轻松,接口代码无非再增加一个函数。
首先上线的是pc端。该栏位处在整个页面的最下面,用户拉到最低显示猜你喜欢,还没上线,pc开发就发现问题了,说出现重复商品。后来反复查看接口,接口无分页,也做过sku,spu,品类商品数量控制之类的校验。后来pc开发发现问题,是因为他们是下拉到可视区域加载,每加载一栏请求一次接口,而接口返回商品有随机性,因此位置不固定,出现不同栏商品重复的情况。首页调用到查看完猜你喜欢栏位,前后调用7次,而且还出现不一致。因此必须要把用户推荐结果进行缓存。回写redis,过期时间设为两分钟。两分钟足够用户浏览完六栏推荐商品了。可问题来了,采用master-slave模式的redis在缓存方面实在是无法满足。为了满足健壮性,只能一个tomcat绑定一个redis,把slave开启可写模式。Nginx 改为IP hash模式。后来通过查看tomcat实际请求日志发现,多数IP基本映射到一台机器。系统可靠性又岌岌可危,眼下首要问题是更换redis集群。可面临一个问题是,前同事配的开发环境用的是Spring MVC 加RedisClientTemplate来读取redis,搜遍baidu也没找到怎么更换到redis cluster。
但是更换redis机群的想法还是没动摇,兵分两路,一路一个人,申请三台机器,另一个同事参考官网文档,部署了redis集群,然后着手处理离线代码,全部改为redis机群,我也在着手把接口更换为读redis机群。此时,很多接口已提前开发完,就等前端调用,开发任务没那么重,也有时间回头看一下代码。也对之前的开发流程做了个梳理,从熟悉数据、业务,到hive脚本数据处理,到spark 算法处理输出到redis,从部署tomcat,redis到nginx负载均衡,基本都是俩个人实现。过程也是从一个坑到另一个坑,基本上都被坑牵着走,还没来的及好好看路。借着这次redis更换,把接口也重构一把。
重构推荐接口
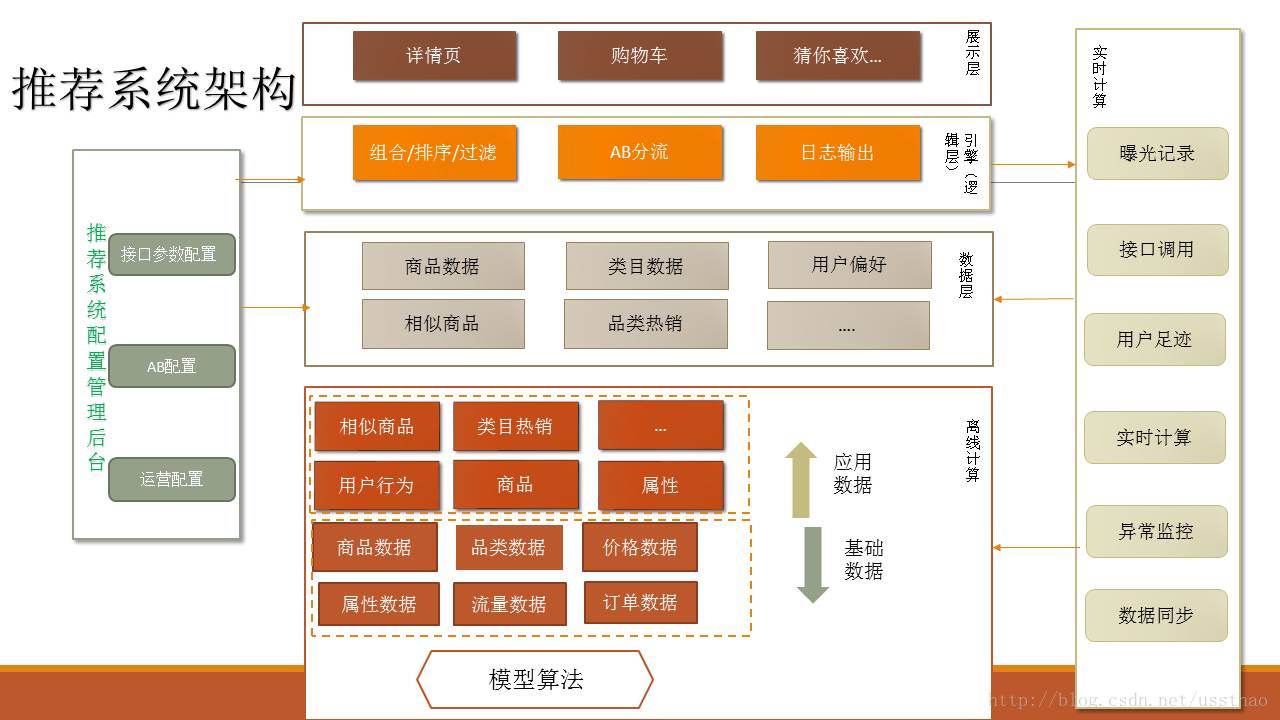
目前百联用到的推荐接口主要还是实现商品推荐,之前的实现方式是每上一个接口,增加一段代码。有的参数都一致,只是重新起个名字,区别可能是pc端和移动端显示方式的差别。当时就想这样的问题,能不能连代码都不用改,只是配置一下就可以了。朝着这个方向开始重新设计,设计的目标朝着可重用、可扩展、可监控、可评估方向进行。
为此,对于商品推荐只提供一个接口,不同栏位用参数进行区分,构造一个统一参数魔板。
首先在数据库为为接口建了一张表,把实物推荐所涉及的参数罗列出来
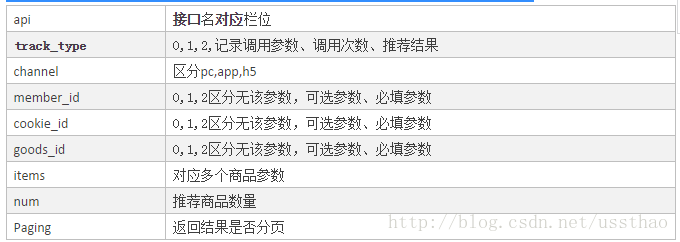
到目前,这些参数满足基本应用,也可以根据需要进行扩展,比如可以传入gps坐标位置,实现基于lbs推荐。
接下来需要考虑的就是,在优化算法效果的时候通常要做ABtest。为此设计了API与method的映射表

在这个设计中,一个栏位对应多个方法,这些方法有序排列,并指定所占流量占比。在用户访问时会分配一个随机数,这个随机数落在哪个区间,即走其对应的方法,这里存在一个问题就是,用户两次访问可能走不同的方法,可以通过缓存当天用户分配随机数解决。因此如果该接口Track_type配置为记录推荐结果,在推荐结果里要增加字段method_code,来区分通过不通方法返回结果,用于后续做转化对比。
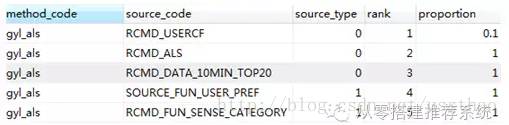
每个方法可能需要多个来源的数据组合起来才能满足栏位需求。而这些数据源又可以分为两类,一类就是前面离线处理的比如算法产生的数据,来源redis里面的,另一类是需要经过变换的数据,例如依据商品ID,找到其所属类目的兄弟类目下的商品。为此我们设计了方法与数据源的对应关系表

以百联移动端首页猜你喜欢为例,api为gyl,channel为1,决定了一个推荐栏位,这个栏位推荐60个商品,需要分页,目前采用的以LFM协同过滤(spark als),这个栏位组合顺序为,前6个为基于usercf的推荐结果(0.1*60),后面是基于lfm算法的。通过观察不同用户推荐效果
发现很多用户都是新用户,基本没历史行为,为这类用户推荐最近10分钟热门top20商品,对于某类用户,有历史行为数据,但是近一段时间没有,为这类用户依据历史用户偏好进行推荐。最后为防止留白,proportion=1表示,尽量把该栏位填满。
对于redis里面数据源,由key前缀和输入参数的取值拼接构成,取值用参数名到传入参数列表中去取。

至此,增加一个栏位推荐接口,如果已有数据源的情况下,就可以通过组合不同数据源来实现,无需改动任何代码。为此app猜你喜欢的接口访问形式如下:
http://rec.bl.com/xx/rec?api=gyl&chan=1&memberId=100000000162626&pNum=1&pSize=10
数据库设计好,数据存在mysql,在原先接口增加mybatis框架,读取配置。配置何时加载哪,第一方案是定时加载,在spring mvc 加入quartz晚上定时加载,每天更新一次,为了即时生效,增加接口调用,通过调用接口,立刻生效。
接口重构从规划到数据库设计到代码更改,接入redis 集群,用了大概一周的时间,又用了一周时间来测试。测试方法不能手工,况且就俩人测试也不全面,于是到tomcat把原先访问日志里面的请求url下载下来,对新接口和新redis重新调用一遍,每个接口用不同的参数组合调用几万次,直到没有bug通过为止。至此redis集群和配置接口升级完毕。
2 引入实时数据处理
前面在规划的时候,就对每个接口,设置了track类型,最初的设想是,记录给每个用户的推荐内容,对于无转化的情况,减少推荐次数,防止用户疲劳,另一个应用是想用推荐无转化情况作为反例,训练个模型,对于详情页实现“千人千面”,人人不同。那么首要问题就是怎么记录这些,kafka必须的,其它电商平台有的,我们也可以有,自己搭建。当然亲自动手的还是另外一个同事,测试环境配上三台kafka,同时我也在接口里面把“猜你喜欢”接口推荐结果写进kafka.这个过程很短,基本不到一周就实现。(很多自己开发的电商平台,可能在开发的时候,就已经规划了埋点,日志收集,对于实时数据的收集不是问题。对于百联采用的是第三方平台,实时收集难度大,实施比较久时间久)
有了kafka就要利用,spark streaming处理实时能用,这个也用上,对于传来的曝光数据进行解析写入hbase,以备后续使用。此后又增加了几个跟实时相关的应用,首先通过修改前端调用接口传递参数,实现三端用户访问商品实时记录。未登陆用户推荐什么,实时热门商品,10分钟更新一次。登陆用户根据当天访问行为1个小时更新一次。三端浏览记录实时同步,pc浏览商品,即刻出现移动端浏览记录里。
此时基本框架构造完成了,基本栏位也覆盖了,之前t+1的商品价格、库存、上下架信息滞后矛盾也突出了。产品经理联系中台,让中台变更信息,实时写入我们kafka。为实现实现价格库存、上下架等信息同步,重新更新商品信息,增加商品上下架和库存信息,之前redis只保存可售有库存商品,这样遗留的问题就是,只有商品上架,无商品下架,只能每天多次清空下架商品。这类实时数据接入,所有问题迎刃而解,距离初次提出这个需求也已快半年之久。
至此,百联推荐系统已初具雏形。这中间又有一个新同事加入到项目组,负载开发推荐运营工具。负责热搜词、商品运营配置工具开发。在这里我们只介绍整个系统从无到有的过程,算法用的也都是一些主流的算法,bayes,usercf,itemcf,als,word2vector,(word2vector在商品相似性计算过程用测试过,主要想实现商品跨品类推荐,类似买了还买)。再下一步在现有框架基础上,来优化算法、增加用户属性和商品属性,实现更精准推荐。
后续优化
丰富算法、丰富数据、提升转化效果,目前已爬取某店三千个类目商品、品牌,价格分布及40几万商品价格、评论数据,做对比分析处理。如有进展再交流。百联刚起步,我们的推荐系统初具雏形。